General
- reliq (C)
My very own query language for html. The reason for it's existence is me not realizing that xpath existed and since i needed a cli tool i've made one. I also didn't know about pup's existence.
It has more concise syntax than xpath and can easily return json, it's also faster, more powerful and extendable than xpath - although compared to xpath 3 it's not really turing complete (yet).
It was first named hgrep but a couple months after it's release another more popular project with the same name was created so people started to get confused.
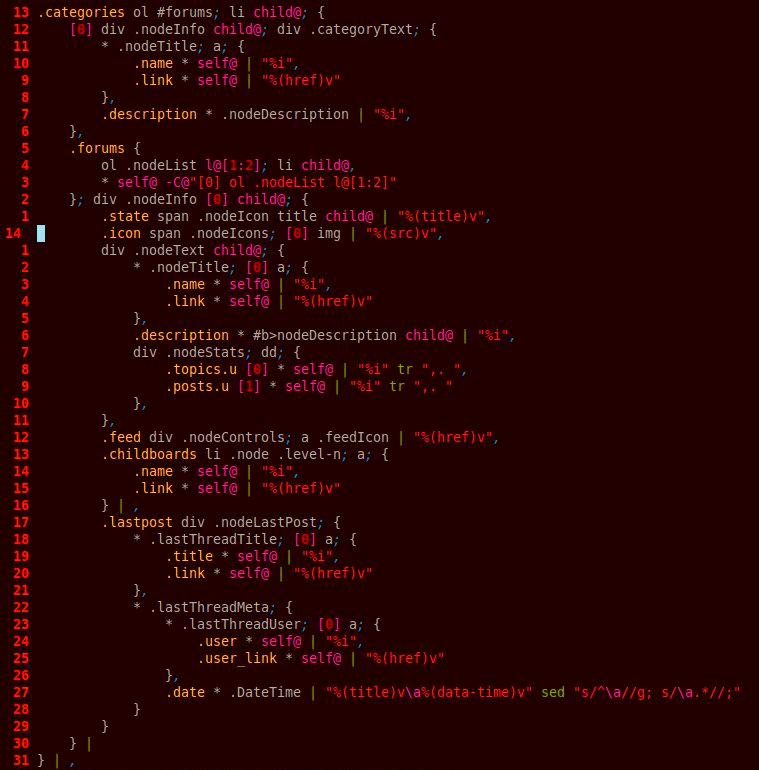
Here's an example of it's syntax xenforo1.reliq, and an image of it with highlighting xenforo1.reliq.png
- csas (C)
A file manager heavily inspired by ranger and lf, but a hundred times faster and more memory efficient (not a hyperbolization). Slightly slower at loading than nnn but sightly more memory efficient.
It was designed to handle directories containing millions of files. It has it's own config file format with a lot of options, calculator, file opener, sxiv integration, workspaces, multiple selections, filters, events system, bulkrename and scout command similar to unix
find(1).It was developed around 2019 and since then has been my only file manager, unfortunately it never got much attention so it's quite unpolished and suited mainly for me.
- treerequests (python)
A wrapper library around requests like libraries which adds features like keeping settings for entire session, list of user agents of browsers, retrying on failures and support for popular html parsers.
It also adds support for
curl(1)like arguments in cli by automatically creating argument section forargparse.Most of it's code was extracted from forumscraper and was developed as drop in solution that polishes rough edges of
requests.- tcomp (python)
Simple html templater that generates static html files from chunks, renders markdown and allows for running commands to generate pages.
This is what i use to manage this site.
- biggusdictus (python)
Library for validating types in python, It adds a lisp like syntax making code more readable.
It comes with a cli tool that processes given json files and outputs python code that precisely validates all of them.
- gitman (bash)
My own set of scripts for dealing with gitolite, github (and possibly many more). It also creates a database like system where i can query all projects by certain stats.
- sunt (bash)
My sophisticated script for transferring and storing files between my remotes, has syntax similar to git.
- reliq-python (python)
Python wrapper for reliq library written with ctypes.
Python has tremendously stupid packaging system that is COMPLETELY undocumented so the only way of learning about it was from github actions of other projects like raylib that are sane enough to use cffi instead of ctypes, what couldn't be learned had to be guessed.
Also pip on windows is retarded and so is pypi.
- kCraft (bash)
My fork of a minecraft launcher, i've added support for fzf and dmenu and useful cli arguments.
{kind=link}
APIs
- neocities (python)
Python api with cli tool for neocities, the main addition to other apis it has
synccommand which synchronizes directories or files without uploading the same files.Developed specifically for uploading this site.
- goip32 (python)
A library and tool that automates html ui of goip32, it allows for viewing stats, sending and receiving SMS.
It theoretically could work for different models (or it would be easy to change it this way) but i don't have any others to test.
I made it for a friend that wanted to make a lot of facebook accounts and maybe start a information campaign before elections :P
- mullvad-api (python)
Library and tool for switching instances, adding new devices and checking status for mullvad.
Not really a complete api but i don't think it'd be safe automating the payment system.
- danegovpl (python)
Tool for getting data from dane.gov.pl, official api is so expandable that it was impractical to create rigid python interface, additional parameters have to be passed as http headers according to the documentation.
It was created as part of a school project.
- fakexy (python)
Tool for getting fake credentials generated by fakexy.com, unfortunatedly the site uses cloudflare so to use it you have to get cookies from the browser or copy them manually.
- hdporncomics (python)
A complete api for hdporncomics.com. You can scrape any page, like any comic, comment, manhwa, also login, comment, respond, view, favorite, view notifications, and remove all of set things.
Above the library it also provides a cli utility for downloading images for any type of page be that comic, manhwa, manhwa chapter, it also allows for scraping metadata of downloaded resources.
There's also a sophisticated tool for scraping the whole site with minimal effort and high reliability with a system of detecting and updating old resources.
The library is well tested, i've written a structure tester for each method. The test themselves are half the library size.
This is the first library that i've documented through python, and second that was written with type annotations.
Scrapers
- forumscraper (python)
Universal, automatic and extensive forum scraper based on reliq. It supports Invision Power Board, PhpBB, Simple Machines Forum, XenForo, XMB, Hacker News, StackExchange and vBulletin engines.
It has replaced my other bash scripts xenforo-scraper, invision-scraper, phpbb-scraper, smf-scraper, stackexchange-scraper and xmbforum-scraper. But it has extended them tremendously by correcting them to more websites, adding support for guessing, identifying, getting boards and forums pages and finding the root of a site.
It can be used as both a cli tool and python library.
- torge (shell)
My tool for quick searching for torrents/books. It has support for thepiratebay, limetorrents, 1337x, rarbg (no longer with us), nyaa and libgen. It integrates well with fzf and shell scripts, it even supports csv and json output. Someone even made a web app on this script.
It's a merged and upgraded version of my previous projects tpb, tlt, t1337x, tnyaa, trarbg and libgen.
- lyryx (python)
A cli tool made for downloading lyrics for music. It supports azlyrics, genius, mojim, tekstowo and lyricsjonk and for some of them can download pretty much the whole sites.
It was a catalyst to creation of reliq, ironically after a couple of years i've rewritten it to learn and compare it to xpath.
- wordpress-madara-scraper (bash)
A scraper made for sites using the madara wordpress extention although focused mainly on the ones with images. It can download the whole sites with structure describing comics and listing links for chapters. It can also immediately download images so I use it as manhwa downloader. This tool is very useful if you want to fill your disk with life time supply of manhwa.
- mangabuddy-scraper (bash)
Similar to wordpress-madara-scraper but made for specific site and since more tailored to it. It can download all metadata about lists, comics and chapters (image links, comments, reviews, basic info) and images. It has 3 modes of scraping: only images, images and basic data, images and all that can be found, you can also get data without images. Overall you could get more than 100GB of metadata out of the whole site.
The only reason for making it was because it had a manhwa i could not find anywhere else and it had very silly anti downloading system, seeing the well defined html structure i've made my scraper for all metadata on this site.
- 1337x-scraper (python)
A scraper and set of instructions for dealing with entirety of 1337x.to
Resulting metadata was supposed to be used in a grand project which flopped before it's creation.
- blu-ray-scraper (python)
A scraper for blu-ray.com, site has daily limit of pages for one ip address.
- 9gag-scraper (python)
A simple scraper for 9gag, i didn't find any way to get list of all ids. So the only methods are to all new ones regularly or to scan like history of users.
After scraping 500GB of metadata i gave up.
- rule34-scraper (python)
A scraper for rule34, i didn't find any use for the metadata though.
- elektroda-scraper (bash)
A scraper for famously not so helpful polish electronic forum. I didn't add it to forumscraper since it's not a forum engine.
- disqus-scraper (bash)
Well, everyone knows disqus, an external commenting system for websites with just a link.
Looking into it i've discovered that they use only one barely obfuscated api auth key that grants you unlimited transfer for all visible things. With this you can very quickly and effortlessly download all comments from any site.
In a month i've downloaded over 100TB of data from it. The best of it is that the script has 107 lines of code and uses only curl and jq as dependencies, there is no scraping it's just downloading all data available, and it's very clean data at that 10/10.
- pornhub-scraper, xhamster-scraper, xvideos-scraper, xnxx-scraper, redtube-scraper, eporner-scraper, youporn-scraper, tube8-scraper, hclips-scraper (bash)
These type of sites have a lot of data, data about humans. It's very easy to scrape and there's a lot of it so why not.
I've tried my best to make them as extensive as possible so they have all data that can be accessed on the site like the views per time in the video, comments, tags, etc. Above that most of them have all other categories than videos like playlists, channels, galleries, pornstars, users.
For the less known sites you can expect around 3GB of data each. For xnxx and xvideos about 9GB each but only about videos (comments included).
More social and popular platforms like pornhub and xhamster give around 30GB without counting users, with them you could get hundreds of GB.
Analyzing the data from them leads to funny conclusions.
- sexstories-scraper (shell)
It download all stories into files named by their titles, there is no special file format, First 8 lines are headers with basic information about them.
This one is an actual goldmine of funny and bad stories. It takes about 1.3GB uncompressed and it downloads quickly so have a laugh.
Others
I have a couple of other projects on my github, although they are not as grand. I also have a lot of useful projects that i did not publish on github since making something usable for others is a pain so they stay useful only for me.
If you have any cool ideas about my projects or new ones you can contact me through email or matrix.